Big data. Un vantaggio davvero?

L'analisi di big data, grazie alle capacità computazionali moderne, ci permette di applicare modelli matematici a quantità di informazioni enormi, traendo così conclusioni su campioni significativi.
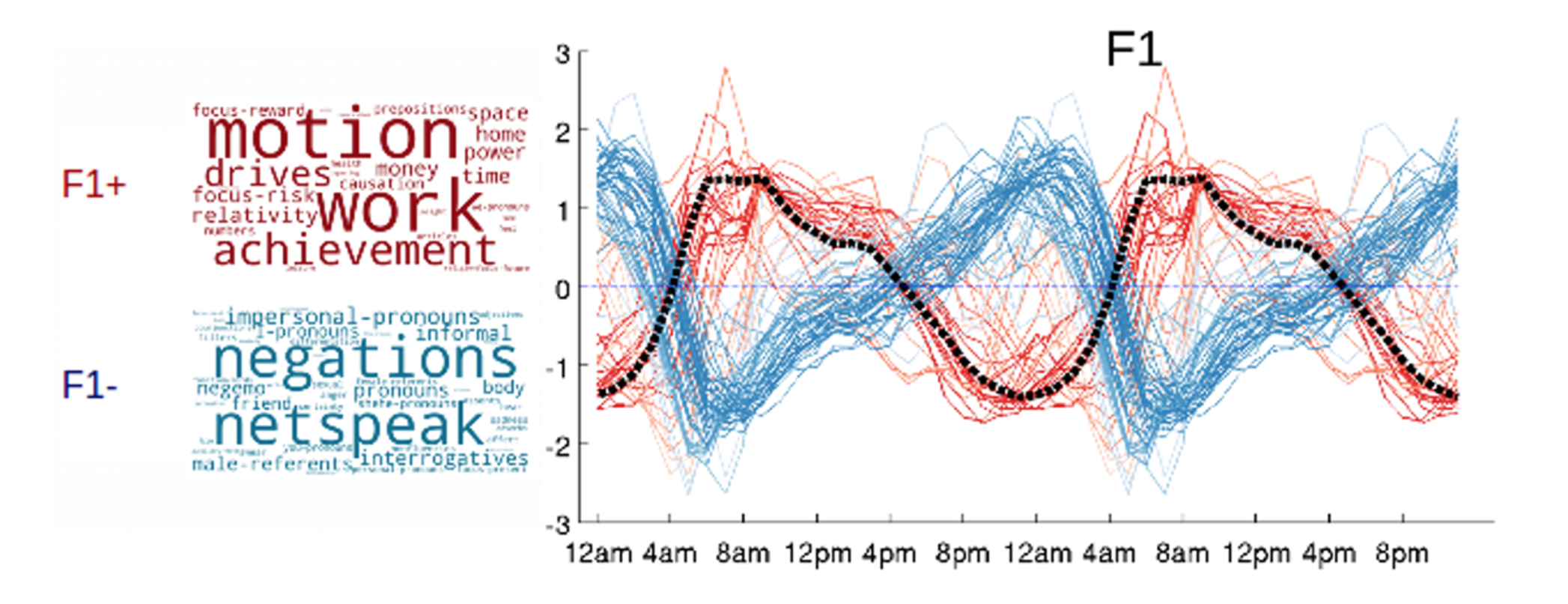
Uno degli esempi che mi ha incuriosito è quello relativo ad una ricerca, pubblicata da Polos One, svolta in UK da un pool di studiosi, che hanno "letto" tweet ogni ora della popolazione di 54 città inglesi.
L'analisi è durata dal 2018 al 2014, e ha registrato 700 milioni di tweet contenenti +7 miliardi di parole.
Con quale obiettivo? Quello di capire il comportamento delle persone in base ai tweet e verificare quindi se ci fossero relazioni tra le tue cose. Applicando un modello chiamato Linguistic Inquiry and Word Count (LIWC) il risultato è stato interessante.
Mentre alla mattina le parole più significative fanno riferimento ai nostri obiettivi, alle attività che vogliamo svolgere, ed hanno un filo conduttore "positivo", verso sera cambiamo letteralmente, facendo uscire le nostre paure.
Non voglio entrare nel dettaglio di questa analisi, che potete approfondire sul sito originale.
Prendo spunto da questa notizia per una riflessione sui big data.
Ho come l’impressione che alcune realtà aziendali abbiano un approccio senza un obiettivo concreto, proprio in questo campo.
Ovvero: tendo a registrare il maggior numero di dati così poi in futuro li potrò utilizzare. Questo modo di pensare l’ho riscontrato in alcune aziende, dove venivano sventolate - a mo’ di vanity metrics - i GB di dati che giornalmente erano immagazzinati nei server aziendali.
Da un lato questo atteggiamento lo capisco: attratti dal basso costo (relativo) per la conservazione di dati in formato digitale, la preoccupazione di lasciare qualcosa che poi potrà servirci è alta, così - per non sbagliare - si tiene tutto: nei processi produttivi, nel marketing, nelle vendite, nell'IT.
Forse è il caso di iniziare a guardare ad un nuovo concetto, quello dei best data: porre una selezione preventiva, limitando quindi i dati da analizzare.
Ma è un approccio realizzabile? E' possibile - e come - selezionare in maniera intelligente i dati aziendali (e personali, perché no) così da memorizzarne solo il minimo indispensabile?
- Quale policy stai adottando per decidere quali dati salvare?
- Meglio quindi big data o best data?
- Selezionare prima o cercare dopo?
Fammi sapere cosa ne pensi nei commenti qui sotto.