LinkedIn data breach? Ecco cosa ho trovato in rete.

Nelle ultime settimane si è diffusa la notizia di un nuovo data breach ai danni di LinkedIn, ovvero un furto di informazioni relative agli utenti iscritti al social network, poi pubblicate su vari canali social.
Non è la prima volta che LinkedIn è sotto i riflettori per un furto di informazioni, anche se la società - ora in mano a Microsoft - ha sempre negato che il loro social network fosse stato violato.
Ma allora, in concreto, cosa è accaduto?
Ho deciso di dare un'occhiata più nel dettaglio e così ho analizzato l'ultimo data base messo in circolazione da alcuni criminali informatici. Ecco cosa ho scoperto.
Il data base.
L'ultimo furto di informazioni annunciato da vari threat actors risale a Luglio scorso: un data base che conterrebbe i dati addirittura di circa 700 milioni di utenti di LinkedIn.
Tale data base è stato poi pubblicato principalmente su due piattaforme, Mega e Google Drive, affinché chiunque lo potesse scaricare.
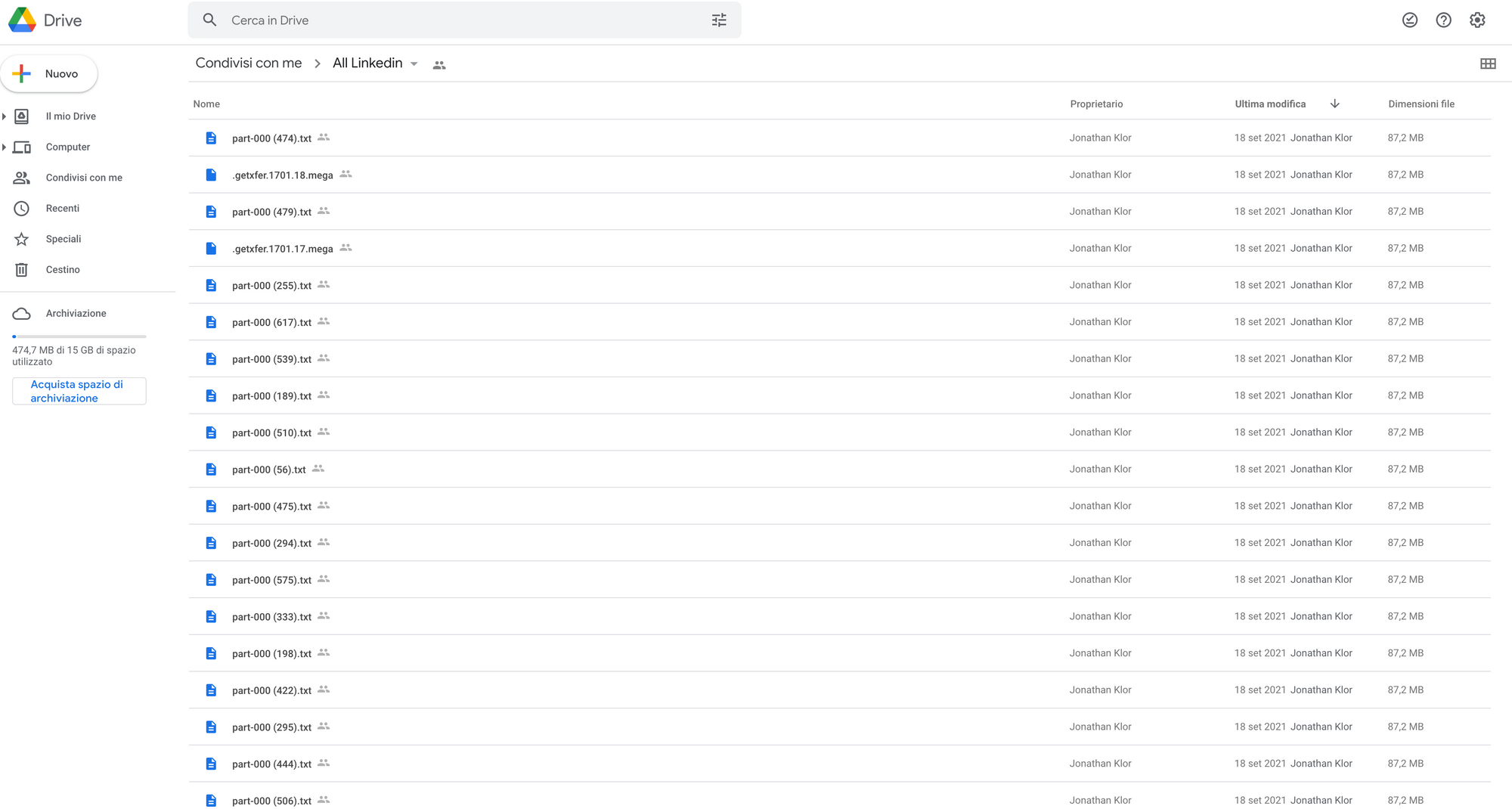
Ho così analizzato i file per capire quali informazioni contenesse: stiamo parlando di più di 130GB di dati suddivisi su 23 file .zip
All'interno degli archivi compressi si trovano due tipologie di file di testo: la prima con nome part-0000 (xxx).txt mentre la seconda con nome part-00xxx.txt
File part-0000 (xxx).txt
Questi file sono presenti in minima parte (ne ho contati 18).
La struttura è molto semplice:
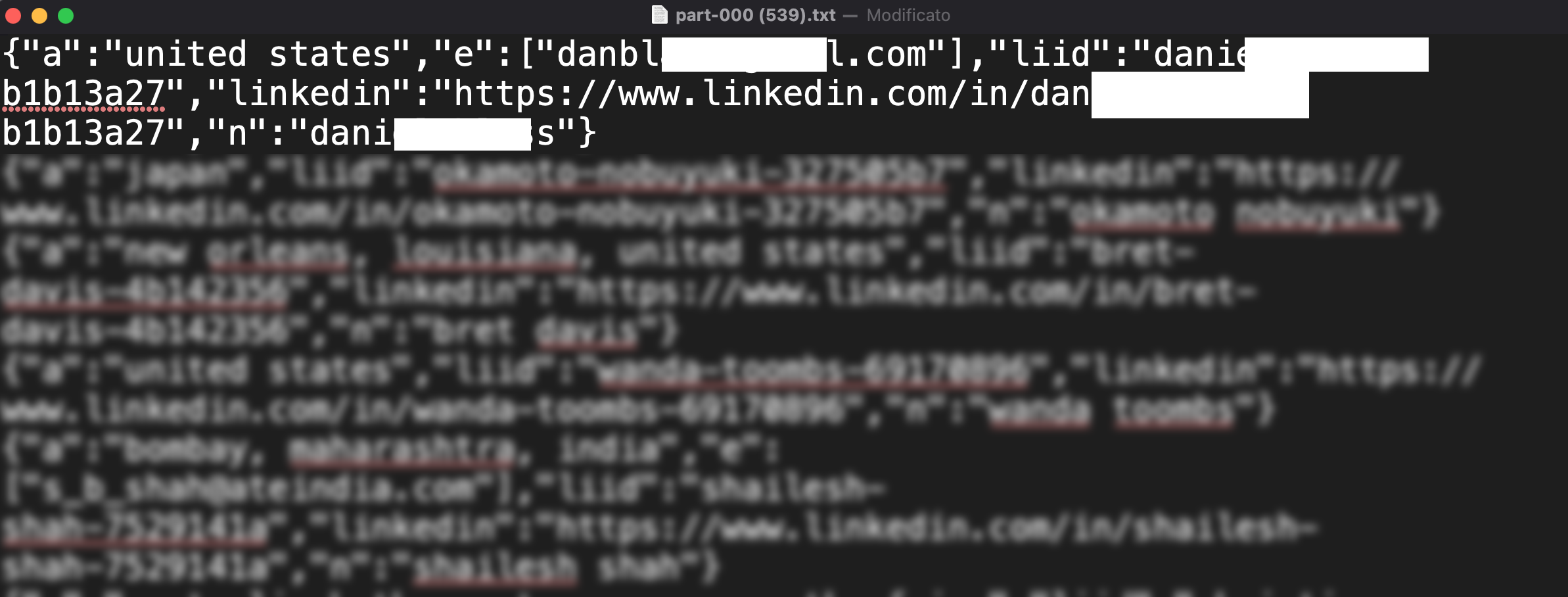
contiene i seguenti campi:
- "a": riporta il paese dell'utente (spesso con indicazione della città)
- "e": email
- "liid": è la usernamen del profilo linkedin
- "linkedin": il link al profilo (che comprende il campo precedente)
- "n": il nome
Ciascun file contiene in media circa 550.000 righe. Il campo "e", quello relativo alla email, è presente in circa 5000 record, ovvero in quasi l'1%.
Moltiplicando il tutto per 18, ovvero il numero totale dei file di questo tipo, ci troviamo di fronte ad un DB con i dati sopra riportati di quasi 10 milioni di utenti e circa 100.000 indirizzi email.
File part-00xxx.txt
Il resto del data base che ho analizzato è composto per la maggior parte da questo secondo tipo di file: in totale ho trovato 154 file, ciascuno da 2,20GB!
Questi file hanno una struttura più articolata perché in pratica riportano molte informazioni sull'utente, sembra aggregate da vari social network: LinkedIn, Facebook e Twitter.
Anche in questo caso, sono presenti le email, ma in quantità percentuale maggiore rispetto al file precedente:
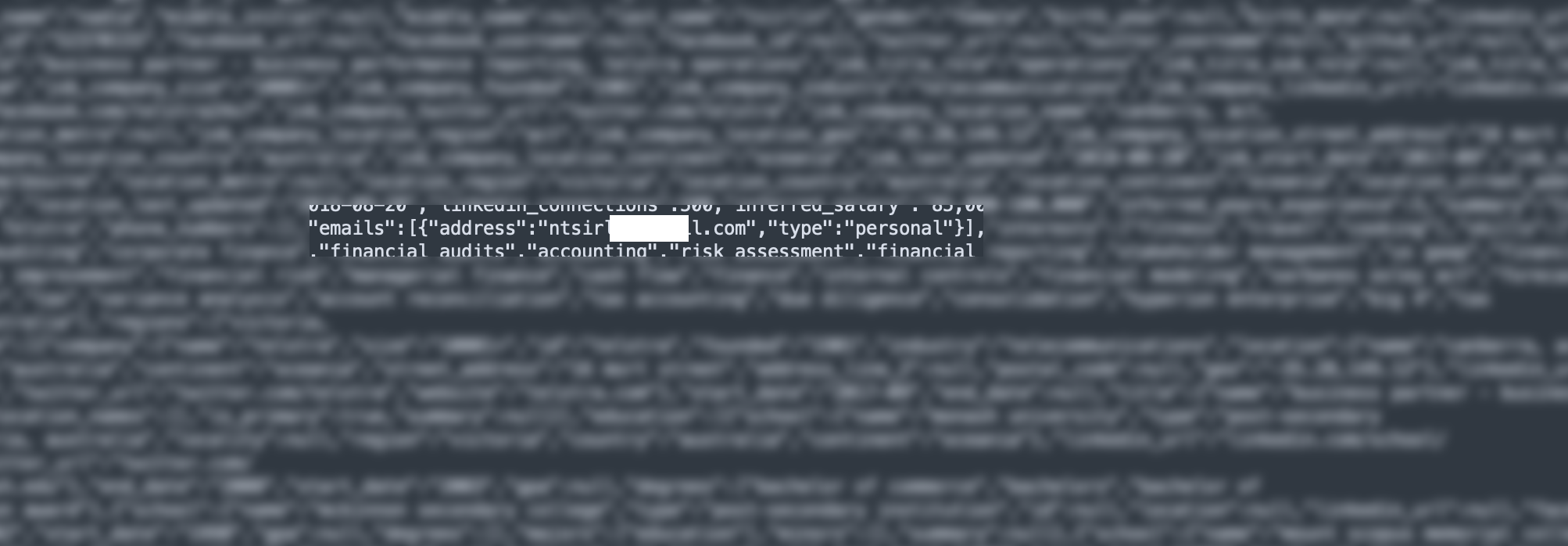
Mediamente, verificando una decina di file, ho trovato la presenza di un totale di 570.000 record e la presenza di oltre 200.000 email.
Moltiplicando il tutto, raggiungiamo - per questa tipologia di file - la ragguardevole cifra di 87 milioni di record che potrebbero contenere quasi 30 milioni di indirizzi email.
Sottolineo "potrebbero" perché non ho avuto il tempo di verificare tutti i file.
Da notare che per ogni record sono presenti molti dati reperibili dal profilo LinkedIn, come ad esempio:
- nome e cognome
- azienda
- località
- link dell'azienda in cui si lavora
- esperienze lavorative
- ruolo
- skill ed interessi
Inoltre ci sono anche i campi che rimandano al profilo Facebook e all'account Twitter dell'utente.
Da dove arrivano queste informazioni?
Difficile rispondere a questa domanda. Sembra il risultato di due attività congiunte.
La prima quella di uno scraping subito da LinkedIn, quindi non un vero e proprio data breach che ha violato il social network. Lo scraping è una attività "passiva" che in sostanza scansiona un sito web e raccoglie le informazioni pubbliche.
Se svolta per raccoglie, aggregare e condividere i dati, è illegale. Ne ho parlato in questo articolo con l'amico avvocato Francesco Cucci.
La seconda è quella di un merging con altri data base. Ovvero sembra che siano stato unite informazioni prelevate illegalmente da varie fonti per costruire un archivio unico.
Ricordo che nell'Aprile scorso è stato pubblicato un data base con i dati di milioni di utenti di Facebook (37 milioni solo quelli italiani) con tanto di numero di cellulare (ne ho parlato qui).
Quali sono i rischi per gli utenti?
Quando informazioni personali afferenti ad un profilo social vengono diffuse, il rischio maggiore è quello della profilazione, ovvero la raccolta e l'utilizzo di tali dati a fini illeciti da parte di criminali informatici.
Sapere i dati anagrafici di una persona, dove vive, dove lavora, i suoi interessi ed infine il suo indirizzo email, lo mette a rischio di un attacco mirato di phishing, ad esempio.
Si potrebbe ricevere una email molto personalizzata che rischia di far cadere nella trappola anche i più attenti.
Cosa fare?
Chiudo con i soliti due consigli:
- Prestare massima attenzione ai dati che condividiamo sui social network (ma non solo), consapevoli del fatto che qualcuno potrebbe utilizzarli per un attacco informatico, magari spacciandosi per un collega o un amico con interessi comuni.
- "Non prendere caramelle dagli sconosciuti": soprattutto quando riceviamo una email (che rimane il vettore di attacco più usato) verifichiamo sempre l'indirizzo del mittente, ed eventualmente chiediamo conferma prima di procedere nel cliccare su eventuali link o scaricare file allegati.
Se ti è piaciuto questo articolo e lo ritieni utile, aiutami nel condividerlo e... iscriviti al mio Blog cliccando qui!
Alla prossima!